Bookmarks 2025-04-30T18:33:25.846Z
by Owen Kibel
29 min read
48 New Bookmarks
| Favicon | Details |
|---|---|
 |
[AI is coming for music, too |

|  | AI Changes Science and Math Forever | Quanta Magazine
| AI Changes Science and Math Forever | Quanta Magazine
Apr 30, 2025
AI Changes Science and Math Forever | Quanta Magazine
Quanta Magazine
An exploration of how artificial intelligence is changing what it means to do science and math, and what it means to be a scientist. |

|  | Qwen3: Think Deeper, Act Faster | Qwen
| Qwen3: Think Deeper, Act Faster | Qwen
Apr 30, 2025
Qwen3: Think Deeper, Act Faster
Qwen
QWEN CHAT GitHub Hugging Face ModelScope Kaggle DEMO DISCORD
Introduction Today, we are excited to announce the release of Qwen3, the latest addition to the Qwen family of large language models. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.
QWEN CHAT GitHub Hugging Face ModelScope Kaggle DEMO DISCORD Introduction Today, we are excited to announce the release of Qwen3, the latest addition to the Qwen family of large language models. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general capabilities, etc., when compared to other top-tier models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro. Additionally, the small MoE model, Qwen3-30B-A3B, outcompetes QwQ-32B with 10 times of activated parameters, and even a tiny model like Qwen3-4B can rival the performance of Qwen2.5-72B-Instruct. We are open-weighting two MoE models: Qwen3-235B-A22B, a large model with 235 billion total parameters and 22 billion activated parameters, and Qwen3-30B-A3B, a smaller MoE model with 30 billion total parameters and 3 billion activated parameters. Additionally, six dense models are also open-weighted, including Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B, under Apache 2.0 license. Models Layers Heads (Q / KV) Tie Embedding Context Length Qwen3-0.6B 28 16 / 8 Yes 32K Qwen3-1.7B 28 16 / 8 Yes 32K Qwen3-4B 36 32 / 8 Yes 32K Qwen3-8B 36 32 / 8 No 128K Qwen3-14B 40 40 / 8 No 128K Qwen3-32B 64 64 / 8 No 128K Models Layers Heads (Q / KV) # Experts (Total / Activated) Context Length Qwen3-30B-A3B 48 32 / 4 128 / 8 128K Qwen3-235B-A22B 94 64 / 4 128 / 8 128K The post-trained models, such as Qwen3-30B-A3B, along with their pre-trained counterparts (e.g., Qwen3-30B-A3B-Base), are now available on platforms like Hugging Face, ModelScope, and Kaggle. For deployment, we recommend using frameworks like SGLang and vLLM. For local usage, tools such as Ollama, LMStudio, MLX, llama.cpp, and KTransformers are highly recommended. These options ensure that users can easily integrate Qwen3 into their workflows, whether in research, development, or production environments. We believe that the release and open-sourcing of Qwen3 will significantly advance the research and development of large foundation models. Our goal is to empower researchers, developers, and organizations around the world to build innovative solutions using these cutting-edge models. Feel free to try Qwen3 out in Qwen Chat Web (chat.qwen.ai) and mobile APP! Key Features Hybrid Thinking Modes Qwen3 models introduce a hybrid approach to problem-solving. They support two modes: Thinking Mode: In this mode, the model takes time to reason step by step before delivering the final answer. This is ideal for complex problems that require deeper thought. Non-Thinking Mode: Here, the model provides quick, near-instant responses, suitable for simpler questions where speed is more important than depth. This flexibility allows users to control how much “thinking” the model performs based on the task at hand. For example, harder problems can be tackled with extended reasoning, while easier ones can be answered directly without delay. Crucially, the integration of these two modes greatly enhances the model’s ability to implement stable and efficient thinking budget control. As demonstrated above, Qwen3 exhibits scalable and smooth performance improvements that are directly correlated with the computational reasoning budget allocated. This design enables users to configure task-specific budgets with greater ease, achieving a more optimal balance between cost efficiency and inference quality. Multilingual Support Qwen3 models are supporting 119 languages and dialects. This extensive multilingual capability opens up new possibilities for international applications, enabling users worldwide to benefit from the power of these models. Language Family Languages & Dialects Indo-European English, French, Portuguese, German, Romanian, Swedish, Danish, Bulgarian, Russian, Czech, Greek, Ukrainian, Spanish, Dutch, Slovak, Croatian, Polish, Lithuanian, Norwegian Bokmål, Norwegian Nynorsk, Persian, Slovenian, Gujarati, Latvian, Italian, Occitan, Nepali, Marathi, Belarusian, Serbian, Luxembourgish, Venetian, Assamese, Welsh, Silesian, Asturian, Chhattisgarhi, Awadhi, Maithili, Bhojpuri, Sindhi, Irish, Faroese, Hindi, Punjabi, Bengali, Oriya, Tajik, Eastern Yiddish, Lombard, Ligurian, Sicilian, Friulian, Sardinian, Galician, Catalan, Icelandic, Tosk Albanian, Limburgish, Dari, Afrikaans, Macedonian, Sinhala, Urdu, Magahi, Bosnian, Armenian Sino-Tibetan Chinese (Simplified Chinese, Traditional Chinese, Cantonese), Burmese Afro-Asiatic Arabic (Standard, Najdi, Levantine, Egyptian, Moroccan, Mesopotamian, Ta’izzi-Adeni, Tunisian), Hebrew, Maltese Austronesian Indonesian, Malay, Tagalog, Cebuano, Javanese, Sundanese, Minangkabau, Balinese, Banjar, Pangasinan, Iloko, Waray (Philippines) Dravidian Tamil, Telugu, Kannada, Malayalam Turkic Turkish, North Azerbaijani, Northern Uzbek, Kazakh, Bashkir, Tatar Tai-Kadai Thai, Lao Uralic Finnish, Estonian, Hungarian Austroasiatic Vietnamese, Khmer Other Japanese, Korean, Georgian, Basque, Haitian, Papiamento, Kabuverdianu, Tok Pisin, Swahili Improved Agentic Capabilities We have optimized the Qwen3 models for coding and agentic capabilities, and also we have strengthened the support of MCP as well. Below we provide examples to show how Qwen3 thinks and interacts with the environment. Pre-training In terms of pretraining, the dataset for Qwen3 has been significantly expanded compared to Qwen2.5. While Qwen2.5 was pre-trained on 18 trillion tokens, Qwen3 uses nearly twice that amount, with approximately 36 trillion tokens covering 119 languages and dialects. To build this large dataset, we collected data not only from the web but also from PDF-like documents. We used Qwen2.5-VL to extract text from these documents and Qwen2.5 to improve the quality of the extracted content. To increase the amount of math and code data, we used Qwen2.5-Math and Qwen2.5-Coder to generate synthetic data. This includes textbooks, question-answer pairs, and code snippets. The pre-training process consists of three stages. In the first stage (S1), the model was pretrained on over 30 trillion tokens with a context length of 4K tokens. This stage provided the model with basic language skills and general knowledge. In the second stage (S2), we improved the dataset by increasing the proportion of knowledge-intensive data, such as STEM, coding, and reasoning tasks. The model was then pretrained on an additional 5 trillion tokens. In the final stage, we used high-quality long-context data to extend the context length to 32K tokens. This ensures the model can handle longer inputs effectively. Due to advancements in model architecture, increase in training data, and more effective training methods, the overall performance of Qwen3 dense base models matches that of Qwen2.5 base models with more parameters. For instance, Qwen3-1.7B/4B/8B/14B/32B-Base performs as well as Qwen2.5-3B/7B/14B/32B/72B-Base, respectively. Notably, in areas like STEM, coding, and reasoning, Qwen3 dense base models even outperform larger Qwen2.5 models. For Qwen3-MoE base models, they achieve similar performance to Qwen2.5 dense base models while using only 10% of the active parameters. This results in significant savings in both training and inference costs. Post-training To develop the hybrid model capable of both step-by-step reasoning and rapid responses, we implemented a four-stage training pipeline. This pipeline includes: (1) long chain-of-thought (CoT) cold start, (2) reasoning-based reinforcement learning (RL), (3) thinking mode fusion, and (4) general RL. In the first stage, we fine-tuned the models using diverse long CoT data, covering various tasks and domains such as mathematics, coding, logical reasoning, and STEM problems. This process aimed to equip the model with fundamental reasoning abilities. The second stage focused on scaling up computational resources for RL, utilizing rule-based rewards to enhance the model’s exploration and exploitation capabilities. In the third stage, we integrated non-thinking capabilities into the thinking model by fine-tuning it on a combination of long CoT data and commonly used instruction-tuning data. This data was generated by the enhanced thinking model from the second stage, ensuring a seamless blend of reasoning and quick response capabilities. Finally, in the fourth stage, we applied RL across more than 20 general-domain tasks to further strengthen the model’s general capabilities and correct undesired behaviors. These tasks included instruction following, format following, and agent capabilities, etc. Develop with Qwen3 Below is a simple guide for you to use Qwen3 on different frameworks. First of all, we provide an standard example of using Qwen3-30B-A3B in Hugging Face transformers: from modelscope import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/Qwen3-30B-A3B" # load the tokenizer and the model tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto" ) # prepare the model input prompt = "Give me a short introduction to large language model." messages = [ {"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=True # Switch between thinking and non-thinking modes. Default is True. ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) # conduct text completion generated_ids = model.generate( **model_inputs, max_new_tokens=32768 ) output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist() # parsing thinking content try: # rindex finding 151668 () index = len(output_ids) - output_ids[::-1].index(151668) except ValueError: index = 0 thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n") content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n") print("thinking content:", thinking_content) print("content:", content) To disable thinking, you just need to make changes to the argument enable_thinking like the following: text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False # True is the default value for enable_thinking. ) For deployment, you can use sglang>=0.4.6.post1 or vllm>=0.8.4 to create an OpenAI-compatible API endpoint: SGLang: python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3 vLLM: vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1 If you use it for local development, you can use ollama by running a simple command ollama run qwen3:30b-a3b to play with the model, or you can use LMStudio or llama.cpp and ktransformers to build locally. Advanced Usages We provide a soft switch mechanism that allows users to dynamically control the model’s behavior when enable_thinking=True. Specifically, you can add /think and /no_think to user prompts or system messages to switch the model’s thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations. Here is an example of a multi-turn conversation: from transformers import AutoModelForCausalLM, AutoTokenizer class QwenChatbot: def init(self, model_name="Qwen/Qwen3-30B-A3B"): self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForCausalLM.from_pretrained(model_name) self.history = [] def generate_response(self, user_input): messages = self.history + [{"role": "user", "content": user_input}] text = self.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) inputs = self.tokenizer(text, return_tensors="pt") response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist() response = self.tokenizer.decode(response_ids, skip_special_tokens=True) # Update history self.history.append({"role": "user", "content": user_input}) self.history.append({"role": "assistant", "content": response}) return response # Example Usage if name == "main": chatbot = QwenChatbot() # First input (without /think or /no_think tags, thinking mode is enabled by default) user_input_1 = "How many r's in strawberries?" print(f"User: {user_input_1}") response_1 = chatbot.generate_response(user_input_1) print(f"Bot: {response_1}") print("----------------------") # Second input with /no_think user_input_2 = "Then, how many r's in blueberries? /no_think" print(f"User: {user_input_2}") response_2 = chatbot.generate_response(user_input_2) print(f"Bot: {response_2}") print("----------------------") # Third input with /think user_input_3 = "Really? /think" print(f"User: {user_input_3}") response_3 = chatbot.generate_response(user_input_3) print(f"Bot: {response_3}") Agentic Usages Qwen3 excels in tool calling capabilities. We recommend using Qwen-Agent to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity. To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself. from qwen_agent.agents import Assistant # Define LLM llm_cfg = { 'model': 'Qwen3-30B-A3B', # Use the endpoint provided by Alibaba Model Studio: # 'model_type': 'qwen_dashscope', # 'api_key': os.getenv('DASHSCOPE_API_KEY'), # Use a custom endpoint compatible with OpenAI API: 'model_server': 'http://localhost:8000/v1', # api_base 'api_key': 'EMPTY', # Other parameters: # 'generate_cfg': { # # Add: When the response content is `this is the thoughtthis is the answer; # # Do not add: When the response has been separated by reasoning_content and content. # 'thought_in_content': True, # }, } # Define Tools tools = [ {'mcpServers': { # You can specify the MCP configuration file 'time': { 'command': 'uvx', 'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai'] }, "fetch": { "command": "uvx", "args": ["mcp-server-fetch"] } } }, 'code_interpreter', # Built-in tools ] # Define Agent bot = Assistant(llm=llm_cfg, function_list=tools) # Streaming generation messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}] for responses in bot.run(messages=messages): pass print(responses) Friends of Qwen Thanks to the support of so many friends. Qwen is nothing without its friends! We welcome more people or organizations to join our community and help us become better! Future Work Qwen3 represents a significant milestone in our journey toward Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI). By scaling up both pretraining and reinforcement learning (RL), we have achieved higher levels of intelligence. We have seamlessly integrated thinking and non-thinking modes, offering users the flexibility to control the thinking budget. Additionally, we have expanded support for a wide range of languages, enhancing global accessibility. Looking ahead, we aim to enhance our models across multiple dimensions. This includes refining model architectures and training methodologies to achieve several key objectives: scaling data, increasing model size, extending context length, broadening modalities, and advancing RL with environmental feedback for long-horizon reasoning. We believe we are transitioning from an era focused on training models to one centered on training agents. Our next iteration promises to bring meaningful advancements to everyone’s work and life.|
|  | Qwen3: Think deeper, act faster | Hacker News
| Qwen3: Think deeper, act faster | Hacker News
Apr 30, 2025
Qwen3: Think deeper, act faster | Hacker News |
| 
Apr 30, 2025
Trump's 100th Day Rally, PELOSI Act Targets Stock Trading, Kamala Returns: AM Update 4/30
YouTube
President Trump celebrates his first 100 days in office with a rally in Michigan. The White House pushes back its tax bill deadline to July 4th amid Republic... |

| | These Startups Are Building Advanced AI Models Without Data Centers | WIRED
Apr 30, 2025
These Startups Are Building Advanced AI Models Without Data Centers
WIRED
A new crowd-trained way to develop LLMs over the internet could shake up the AI industry with a giant 100 billion-parameter model later this year.
Flower AI and Vana, two startups pursuing unconventional approaches to building AI, worked together to create the new model, called Collective-1. Flower created techniques that allow training to be spread across hundreds of computers connected over the internet. The company’s technology is already used by some firms to train AI models without needing to pool compute resources or data. Vana provided sources of data including private messages from X, Reddit, and Telegram. Collective-1 is small by modern standards, with 7 billion parameters—values that combine to give the model its abilities—compared to hundreds of billions for today’s most advanced models, such as those that power programs like ChatGPT, Claude, and Gemini. Nic Lane, a computer scientist at the University of Cambridge and cofounder of Flower AI, says that the distributed approach promises to scale far beyond the size of Collective-1. Lane adds that Flower AI is partway through training a model with 30 billion parameters using conventional data, and plans to train another model with 100 billion parameters—close to the size offered by industry leaders—later this year. “It could really change the way everyone thinks about AI, so we’re chasing this pretty hard,” Lane says. He says the startup is also incorporating images and audio into training to create multimodal models. Distributed model-building could also unsettle the power dynamics that have shaped the AI industry. AI companies currently build their models by combining vast amounts of training data with huge quantities of compute concentrated inside data centers stuffed with advanced GPUs that are networked together using super-fast fiber-optic cables. They also rely heavily on datasets created by scraping publicly accessible—although sometimes copyrighted—material, including websites and books. The approach means that only the richest companies, and nations with access to large quantities of the most powerful chips, can feasibly develop the most powerful and valuable models. Even open source models, like Meta’s Llama and R1 from DeepSeek, are built by companies with access to large data centers. Distributed approaches could make it possible for smaller companies and universities to build advanced AI by pooling disparate resources together. Or it could allow countries that lack conventional infrastructure to network together several data centers to build a more powerful model. Lane believes that the AI industry will increasingly look towards new methods that allow training to break out of individual data centers. The distributed approach “allows you to scale compute much more elegantly than the data center model,” he says. Helen Toner, an expert on AI governance at the Center for Security and Emerging Technology, says Flower AI’s approach is “interesting and potentially very relevant” to AI competition and governance. “It will probably continue to struggle to keep up with the frontier, but could be an interesting fast-follower approach,” Toner says. Divide and Conquer Distributed AI training involves rethinking the way calculations used to build powerful AI systems are divided up. Creating an LLM involves feeding huge amounts of text into a model that adjusts its parameters in order to produce useful responses to a prompt. Inside a data center the training process is divided up so that parts can be run on different GPUs, and then periodically consolidated into a single, master model. The new approach allows the work normally done inside a large data center to be performed on hardware that may be many miles away and connected over a relatively slow or variable internet connection. Some big players are also exploring distributed learning. Last year, researchers at Google demonstrated a new scheme for dividing and consolidating computations called DIstributed PAth COmposition (DiPaCo) that enables more efficient distributed learning. To build Collective-1 and other LLMs, Lane and academic collaborators in the UK and China developed a new tool called Photon that makes distributed training more efficient. Photon improves upon Google’s approach, Lane says, with a more efficient approach to representing the data in a model and a more efficient scheme for sharing and consolidating training. The process is slower than conventional training but is more flexible, allowing new hardware to be added to ramp up training, Lane says. Photon was developed in collaboration with researchers at Beijing University of Posts and Telecommunications and Zhejiang University in China. The group released the tool under an open source license last month, allowing anyone to make use of the approach. Flower AI’s partner in the effort to build Collective-1, Vana, is developing new ways for users to share personal data with AI builders. Vana’s software allows users to contribute private data from platforms like X and Reddit to training a large language model, and potentially specify what kind of end uses are permitted or even benefit financially from their contributions. Anna Kazlauskas, cofounder of Vana, says the idea is to make untapped data available for AI training and also to give users more control over how their information is used for AI. “This is data that isn’t usually able to be included in AI models because it’s not publicly available,” Kazlauskas says, “and is the first time that data directly contributed by users is being used to train a foundation model, with users given ownership of the AI model their data creates.” Mirco Musolesi, a computer scientist at University College London, says a key benefit of the distributed approach to AI training is likely to be that it unlocks new kinds of data. “Scaling this to frontier models would allow the AI industry to leverage vast amounts of decentralized and privacy-sensitive data, for example in health care and finance, for training without the risks associated with data centralization,” he says. What do you think of distributed machine learning? Would you contribute your data to a model like Collective-1? Send an email to hello@wired.com or comment below to let me know.|

|
Apr 30, 2025
Trump Celebrates 100 Days Amid RECORD Lawsuits & Unconstitutional Judicial Actions | Timcast IRL
YouTube
SUPPORT THE SHOW BUY CAST BREW COFFEE NOW - https://castbrew.com/Sign Up For Exclusive Episodes At https://timcast.com/Merch - https://timcast.creator-spring... |

|
Apr 30, 2025
Violent Democrat MOB ATTACKS Jack Posobiec At Rally, Democrat Rep Jamie Raskin Accused Of INCITEMENT
YouTube
The Green Room - https://rumble.com/playlists/aa56qw_g-j0BUY CAST BREW COFFEE TO FIGHT BACK - https://castbrew.com/Join The Discord Server - https://timcast.... |

|
Apr 30, 2025
POTUS: "In a few short weeks, we've achieved the most secure border in American history, by far."
YouTube
#POTUS #Trump #donaldjtrump #donaldtrump #presidenttrump #usa #America |

|
Apr 30, 2025
President Trump Participates in a Cabinet Meeting, Apr. 30, 2025
YouTube
The White House |

|
Apr 30, 2025
RFK's Crackdown Is LONG Overdue
YouTube
The Green Room - https://rumble.com/playlists/aa56qw_g-j0BUY CAST BREW COFFEE TO FIGHT BACK - https://castbrew.com/Join The Discord Server - https://timcast.... |

|
Apr 30, 2025
Trump Calls ABC FAKE NEWS To Their FACES #shorts #trump
YouTube
The Green Room - https://rumble.com/playlists/aa56qw_g-j0BUY CAST BREW COFFEE TO FIGHT BACK - https://castbrew.com/Join The Discord Server - https://timcast.... |

|
Apr 30, 2025
Episode 2825 CWSA 04/30/25
YouTube
Lots of fake news, fake science, and fake polls and more fun~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~If you would like to enjoy this same content plus bonus ... |

| 
Apr 30, 2025
Trump spars with ABC’s Terry Moran over tariff policy, deportations and Ukraine war in testy interview: ‘Everything’s going to be just fine’
New York Post
Moran pressed Trump, 78, on the 145% levies he’s imposed on China, arguing that the tariff is bound to “raise prices on everything” – a claim the president strongly disagreed with. |

|
Apr 30, 2025
Trump mortifies ABC News reporter with scathing remark on why he was picked for highly sought interview
New York Post
On Tuesday, the Oval Office face-to-face discussion broke down when the commander in chief and Moran began to debate suspected MS-13 gang member Kilmar Abrego Garcia’s tattoos. |

|
Apr 30, 2025
Trump SLAMS Reporter TO HIS FACE, Calls Him FAKE NEWS IN Hilarious ROAST, Media CAUGHT LYING
YouTube
The Green Room - https://rumble.com/playlists/aa56qw_g-j0BUY CAST BREW COFFEE TO FIGHT BACK - https://castbrew.com/Join The Discord Server - https://timcast.... |

| | USDA Ends a Biden Administration Injustice - WSJ
Apr 30, 2025 |
|  | BLACKIE LAWLESS Says 'Censorship Is Worse Now Than It Was In The '80s', Calls DONALD TRUMP 'A Winner' - BLABBERMOUTH.NET
| BLACKIE LAWLESS Says 'Censorship Is Worse Now Than It Was In The '80s', Calls DONALD TRUMP 'A Winner' - BLABBERMOUTH.NET
Apr 29, 2025
BLACKIE LAWLESS Says 'Censorship Is Worse Now Than It Was In The '80s', Calls DONALD TRUMP 'A Winner'
BLABBERMOUTH.NET
In a new interview with Mane Campos of Chile's Heavyfonía, Blackie Lawless of W.A.S.P., whose single "Animal (F**k Like a Beast)", landed at No. 9 on the PMRC's (Parents' Music Resource Center) "Filthy Fifteen" 40 years ago, spoke about the importance of free speech. He said (as transcribed by BLABB... |

| | In campaign-style rally, Trump touts accomplishments in Warren
Apr 29, 2025
In campaign-style rally, Trump touts accomplishments, roasts Democrats, in Warren
Detroit Free Press
President Trump returned to Michigan for the first time in his second term to celebrate 100 days in office. |

|  | Breaking the Enum Habit: Why TypeScript Developers Need a New Approach
| Breaking the Enum Habit: Why TypeScript Developers Need a New Approach
Apr 29, 2025
Breaking the Enum Habit: Why TypeScript Developers Need a New Approach
Angular Space
There is a lot of talk within the Angular and TypeScript community as a whole about the usage of enums. It seems to be a hill both proponents and opponents are willing to die on and defend harshly. Enums are a commonly used TypeScript feature that offers tremendous value and |

| | Is AI “normal”?
Apr 29, 2025 |
|
Apr 29, 2025
Mark Zuckerberg – Meta’s AGI Plan
YouTube
Zuck on:* Llama 4, benchmark gaming, open vs source* Intelligence explosion, business models for AGI* DeepSeek/China, export controls, & Trump* Orion glasses... |

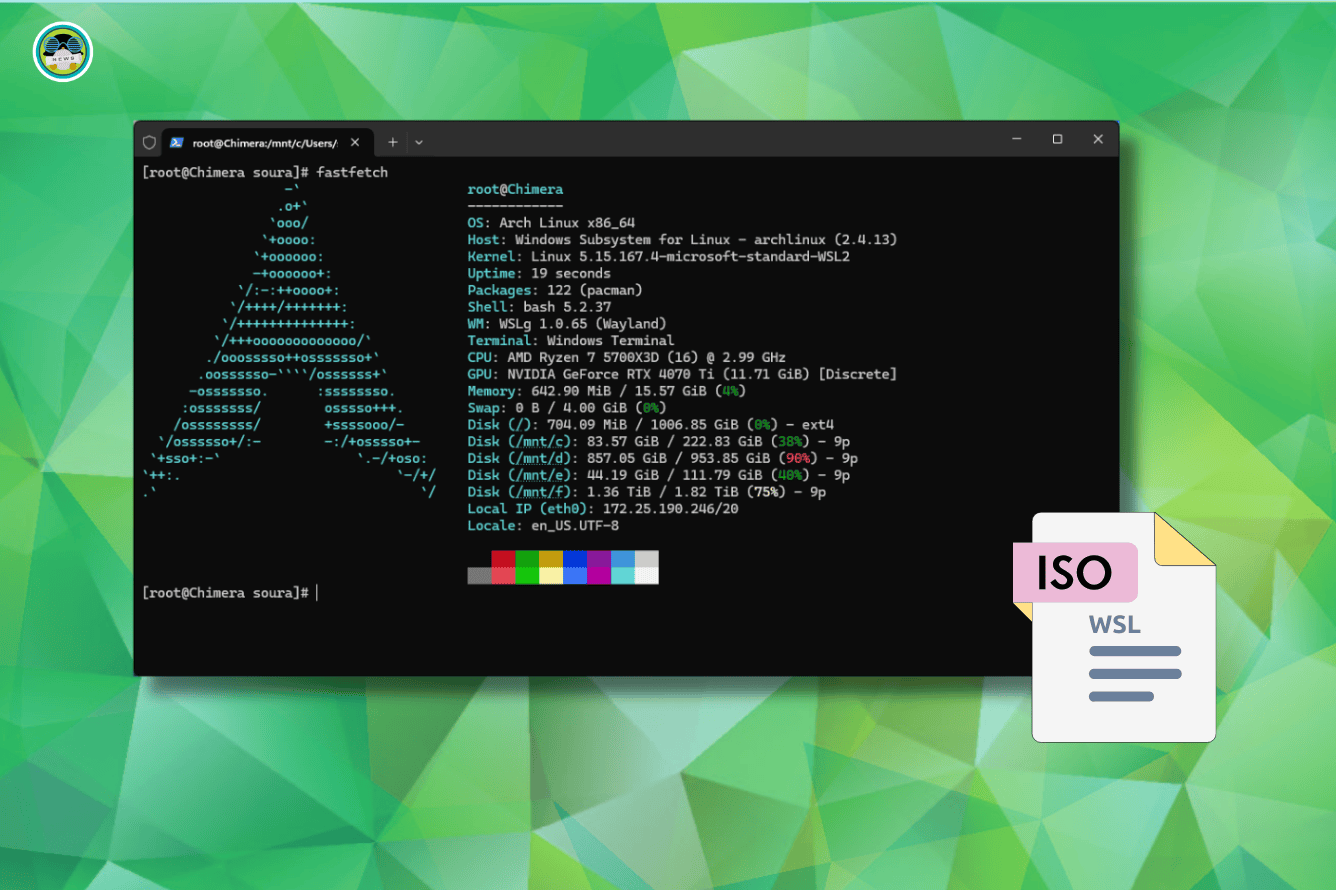
|  | You Can Now Officially Run Arch Linux Inside Windows
| You Can Now Officially Run Arch Linux Inside Windows
Apr 29, 2025
You Can Now Officially Run Arch Linux Inside Windows
It's FOSS News
Arch Linux is now officially available on Windows Subsystem for Linux (WSL). |
| 
Apr 29, 2025
A Single Cubic Millimeter of Brain Tissue May Have Just Changed Neuroscience Forever
Popular Mechanics
Understanding human intelligence, here we come.
A new package of papers examines the largest map yet of mammalian brain tissue.The map shows one cubic millimeter worth of neurons in the visual cortex of a mouse.Many brain functions, particularly the senses, are similar across different mammal species.Scientists have mapped an unprecedentedly large portion of the brain of a mouse. The cubic millimeter worth of brain tissue represents the largest piece of a brain we’ve ever understood to this degree, and the researchers behind this project say that the mouse brain is similar enough to the human brain that they can even extrapolate things about us. A cubic millimeter sounds tiny—to us, it is tiny—but a map of 200,000 brain cells represents just over a quarter of a percent of the mouse brain. In brain science terms, that’s extraordinarily high. A proportionate sample of the human brain would be 240 million cells.Within the sciences, coding and computer science can sometimes overshadow the physical and life sciences. Rhetoric about artificial intelligence has raced ahead with terms like “human intelligence,” but the human brain is not well enough understood to truly give credence to that idea. Scientists have worked for decades to analyze the brain, and they’re making great progress despite the outsized rhetoric working against them.That said, artificial intelligence designed for specific tasks is essential to research like this. In a series of eight papers in the peer reviewed journal Nature, the team behind the Machine Intelligence from Cortical Networks (MICrONS) project—hailing from the Allen Institute, Baylor College of Medicine, and Princeton University—described how they used machine learning to “reverse engineer the algorithms of the brain.”The field in which scientists map the brain and other parts of the nervous system (of humans or any other creature) is called connectomics. The term comes from the same suffix as in biome or genome, referring to a complete picture or map of something. This work expands on the connectome—which is only the physical map—by adding data about each neuron’s function.In one of the team’s papers, the researchers were able to make an overall classifying system to cover 30,000 neurons by their different shapes, or morphologies. These neurons are excitatory, meaning they’re involved with transmitting messages in the brain. The alternative to excitatory is inhibitory, which is circuitry that stops a message from being passed, like an insulator.Inhibitory neuron shapes are better understood, partly because their shapes can be separated into diverse (but discrete) groups. In this study, scientists used machine learning to help classify excitatory neurons, which seem to need a more complicated classifying system. By turning the neurons into measurements, observations ,and layers, the scientists could then use statistical methods to find how often certain types or qualities of these cells appeared. This may sound like an oxymoron, but code can generalize more precisely than human scientists are able to.“(1) Superficial L2/3 neurons are wider than deep ones; (2) L4 neurons in V1 are less tufted than those in HVAs; (3) the basal dendrites of a subset of atufted L4 neurons in V1 avoid reaching into L5; (4) excitatory cortical neurons form mostly a continuum with respect to dendritic morphology, with some notable exceptions.”The conclusion about a continuum is really important. Having categories for neurons can be and has been useful in studying the brain, but computing power can deepen this understanding and add a great deal of nuance. With more information, we can turn broad types into something more individualized.Another paper in the set found confirmation of an existing theory that “like connects like” within neuron structures. Neurons that perform certain tasks in the visual cortex of the mouse brain reach out and link up with each other, whether they’re adjacent or layers apart. Because of the size of this dataset, the scientists were able to extend this established theory into further-away parts of the brain region. And since even this large mapping of brain tissue is still very incomplete, the number of “like” neurons is likely even higher in reality.The data and maps from this project are available for the public to check out by following the instructions on their website. It’s wild that you don’t even have to download anything—you can map the brain using your web browser.|

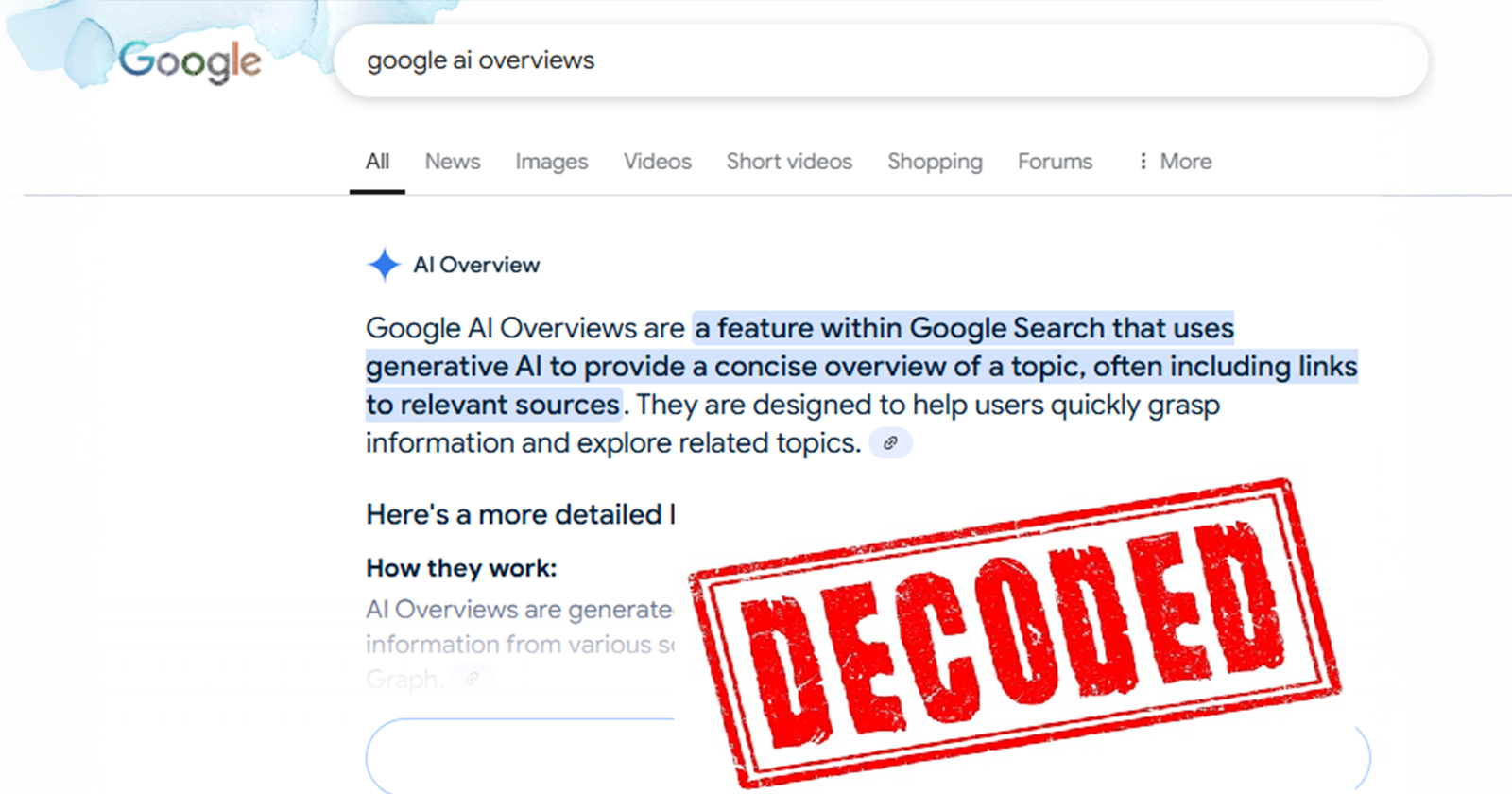
|  | We Figured Out How AI Overviews Work (& Built A Tool To Prove It)
| We Figured Out How AI Overviews Work (& Built A Tool To Prove It)
Apr 29, 2025
We Figured Out How AI Overviews Work [& Built A Tool To Prove It]
Search Engine Journal
Unlock the secrets of AI Overviews and realign your SEO strategy for improved visibility and relevance on Google. |
|
Apr 29, 2025
LIVE: Donald Trump speaks at Michigan rally
YouTube
Donald Trump is giving a speech on his first 100 days in office at a rally in Warren, Michigan, on Tuesday at 5 p.m. CT. |

|
Apr 29, 2025
President Trump delivers remarks to the Michigan National Guard on 100th day in office
YouTube
President Donald Trump delivers remarks to the Michigan National Guard on 100th day in office #FoxNews #TrumpSubscribe to Fox News! https://bit.ly/2vBUvASWat... |

|
Apr 29, 2025
LIVE: Trump gives speech at rally for first 100 days back in White House
YouTube
President Donald Trump to give speech at rally for first 100 days back in White HouseHere's everything you need to know about Trump's term so far: https://b... |

| | Ivanka Trump on X: "Theo debuting his first original composition for Grandpa last night at The White House 🥰 https://t.co/D6L4wQaH2V" / X
Apr 29, 2025 |
| 
Apr 29, 2025
RFK Jr. said many autistic people will never write a poem − even though there’s a rich history of neurodivergent poets and writers
The Conversation
Reading and writing poetry, which is anchored in patterns of words, images, sounds and forms, is particularly well suited for people with autism. |

| | Google’s NotebookLM Audio Overviews adds more than 50 languages
Apr 29, 2025
NotebookLM Audio Overviews are now available in over 50 languages
Google
Learn more about NotebookLM’s Audio Overviews feature and its expansion to more than 50 languages. |

| | Qwen2.5 Omni: See, Hear, Talk, Write, Do It All!
Apr 29, 2025
Qwen2.5 Omni: See, Hear, Talk, Write, Do It All!
Simon Willison’s Weblog
I'm not sure how I missed this one at the time, but last month (March 27th) Qwen released their first multi-modal model that can handle audio and video in addition … |
| | Dawn 711 🇺🇸🇺🇸 on X: "Absolutely stunning! Wow!!" / X
Apr 29, 2025 |
| | Julie on X: "@DawnAnd91320913 Oh well. Twice the people for me to torment! No! Tell the poster to fuck right off. X cares not and you will feel better." / X
Apr 29, 2025 |
| | Julie on X: "@w_terrence You are so much prettier than, you know who. Hoo hoo hoohoohoo. Hoo?" / X
Apr 29, 2025 |
| ![]() | Long-awaited Harvard antisemitism report shows intense campus hostility to Jews, Israelis | The Times of Israel
| Long-awaited Harvard antisemitism report shows intense campus hostility to Jews, Israelis | The Times of Israel
Apr 29, 2025
Long-awaited Harvard antisemitism report shows intense campus hostility to Jews, Israelis | The Times of Israel |

|
Apr 29, 2025
POTUS announces 21 brand new F-15EX Eagle II Fighter Jets.
YouTube
#fighterjet #jet #military #trump #presidenttrump #potus #secdef #defense |
